
FUSE分布式存储:云原生时代的高性能文件系统解决方案
FUSE分布式存储通过将用户空间文件系统与云对象存储结合,为企业提供了一个低成本、高性能的云原生存储解决方案,特别适用于AI模型部署和大数据应用场景。


随着人工智能和大数据应用的快速发展,传统的存储解决方案正面临前所未有的挑战。在这个背景下,FUSE(Filesystem in Userspace)分布式存储作为一种创新的存储技术,正在重新定义我们对高性能、可扩展存储系统的理解。
什么是FUSE分布式存储?
FUSE技术基础
FUSE是一项革命性的文件系统技术。要理解它的价值,我们先来看看传统文件系统的局限:
传统文件系统的问题:
- 传统文件系统(如ext4、NTFS)运行在操作系统内核空间
- 开发和调试需要内核编程知识,门槛极高
- 一旦出现bug可能导致系统崩溃
- 修改和扩展困难,需要重新编译内核
FUSE的创新之处:
FUSE将文件系统的实现从内核空间移到了用户空间,这意味着:
- 普通程序员可以用Python、C++等常见语言开发文件系统
- 文件系统崩溃不会影响整个操作系统
- 可以轻松集成网络存储、加密、压缩等功能
- 支持热更新和动态配置
工作原理
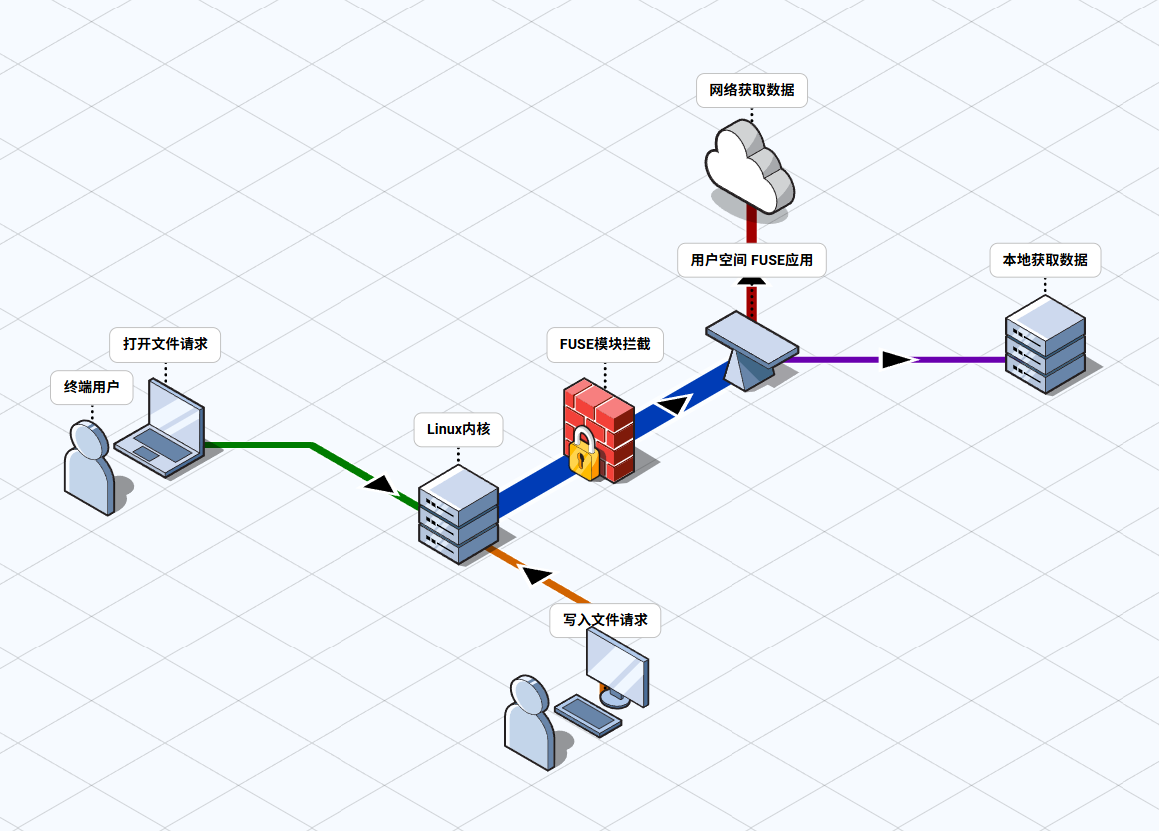
当应用程序要读取一个文件时:
- 应用发起文件操作请求(如打开文件)
- Linux内核的FUSE模块拦截这个请求
- 请求被转发给用户空间的FUSE程序
- FUSE程序处理请求(可能从网络获取数据)
- 数据返回给应用程序,就像操作本地文件一样
FUSE分布式存储的实际应用
在云计算环境中,FUSE分布式存储发挥了巨大价值:
解决的核心问题:
- 对象存储(S3、GCS)便宜但API复杂,应用程序需要大量改造
- 传统NFS/网络文件系统昂贵且扩展性差
- 需要在成本、性能、易用性之间找到平衡
FUSE的解决方案:
通过FUSE,我们可以将云端的对象存储"伪装"成本地文件系统:
- 应用程序无需修改,继续使用标准的文件操作(open、read、write)
- 背后实际访问的是S3、GCS等低成本对象存储
- 享受对象存储的经济性和无限扩展能力
- 通过智能缓存获得接近本地存储的性能
FUSE分布式存储的核心优势
1. 极具竞争力的成本优势
相比传统的网络文件系统(NFS),FUSE分布式存储在成本方面具有压倒性优势。以10TB的模型存储为例:
- NFS方案:每月费用高达2,320-6,920美元
- FUSE方案:每月费用仅需220美元左右
这意味着FUSE方案可以将存储成本降低多达95%,这对于需要存储大量AI模型权重文件的企业来说具有重要意义。
2. 卓越的可扩展性表现
FUSE分布式存储在扩展性方面表现突出:
水平扩展能力:几乎无限制的水平扩展能力,每个客户端独立获取数据,不会因为客户端数量增加而产生性能瓶颈。
高并发性能:当50个节点同时拉取模型时,FUSE系统可以实现25 GB/s的总吞吐量,而传统NFS往往在2.5 GB/s处饱和。
无单点故障:内置的冗余和可用性机制,每个客户端都具有独立的故障恢复能力。
3. 智能化的存储管理
现代FUSE实现具备多项智能化特性:
- 懒加载机制:仅在需要时加载模型层,避免不必要的数据传输
- 智能缓存策略:支持本地缓存和智能淘汰策略
- 分层存储:热数据存储在SSD,温数据存储在CDN,冷数据存储在对象存储
主流云平台的FUSE解决方案
AWS Mountpoint for S3
- 吞吐量:400-500 MB/s
- 成本:标准存储$23/TB/月,高性能存储$160/TB/月
- 特点:针对大文件读取优化,支持弹性扩展和LRU缓存淘汰
Google Cloud Storage FUSE
- 吞吐量:200-300 MB/s
- 成本:$20/TB/月(标准存储)
- 特点:良好的小文件性能,支持可配置TTL和并行下载
Azure BlobFuse2
- 吞吐量:150-250 MB/s
- 成本:$18.40/TB/月(标准存储)
- 特点:支持三种缓存模式(块、文件、流式)
跨云平台的FUSE解决方案
对于多云环境,还有一些优秀的跨平台FUSE解决方案:
JuiceFS
- 吞吐量:约1000 MB/s读取
- 许可证:Apache 2.0(社区版)
- 成本:云服务$0.02/GB/月
Alluxio
- 吞吐量:约1500 MB/s(取决于RAM/CPU/网络)
- 许可证:Apache 2.0(核心)+ 企业商业版
- 特点:内存级别的数据访问速度
针对机器学习工作负载的优化策略
为了充分发挥FUSE分布式存储在AI/ML场景下的优势,需要进行针对性的调优:
页面大小优化
将默认的4KB页面大小增加到1-2MB,以匹配模型文件的块大小特征。
预取策略
配置积极的预读策略(256MB+),因为模型加载通常是顺序的。
并发配置
为多GB模型设置8-12个并行流线程数量。
缓存TTL
在Pod调度之前触发缓存预填充,确保模型已经缓存在本地。
实际部署考量
在生产环境中部署FUSE分布式存储时,需要考虑以下几个关键因素:
工作负载特征分析
不同的应用场景对存储系统的要求不同。对于大型模型推理服务,需要重点关注大文件的顺序读取性能;对于训练工作负载,则需要平衡读写性能。
网络带宽规划
FUSE系统的性能很大程度上取决于网络带宽。在设计系统架构时,需要确保网络带宽不会成为瓶颈。
缓存策略设计
合理的缓存策略可以显著提升系统性能。需要根据数据访问模式设计多级缓存策略。
FUSE分布式存储的未来发展
FUSE分布式存储正在向着更高性能、更智能的方向发展:
性能提升
通过内核旁路和并行化技术,未来的FUSE系统有望达到5-10 GB/s的吞吐量,与NVMe存储性能相媲美。
POSIX兼容性
不断完善的POSIX操作支持,确保PyTorch、JAX、TensorFlow等主流机器学习框架的完全兼容。
智能化演进
自动理解和优化机器学习访问模式,无需人工调优即可获得最佳性能。
总结
FUSE分布式存储代表了存储技术发展的一个重要方向。它成功地将对象存储的经济性与传统文件系统的易用性结合在一起,为云原生应用提供了一个高性能、低成本的存储解决方案。
对于正在进行数字化转型的企业,特别是那些大量使用AI/ML工作负载的组织,FUSE分布式存储提供了一个值得认真考虑的存储策略选择。随着技术的不断成熟和生态的完善,FUSE分布式存储有望在未来的云计算环境中扮演更加重要的角色。
通过合理的规划和部署,企业可以利用FUSE分布式存储实现存储成本的大幅降低,同时获得更好的性能和可扩展性,为业务的快速发展提供强有力的技术支撑。



