
面对高并发前置反向代理的价值

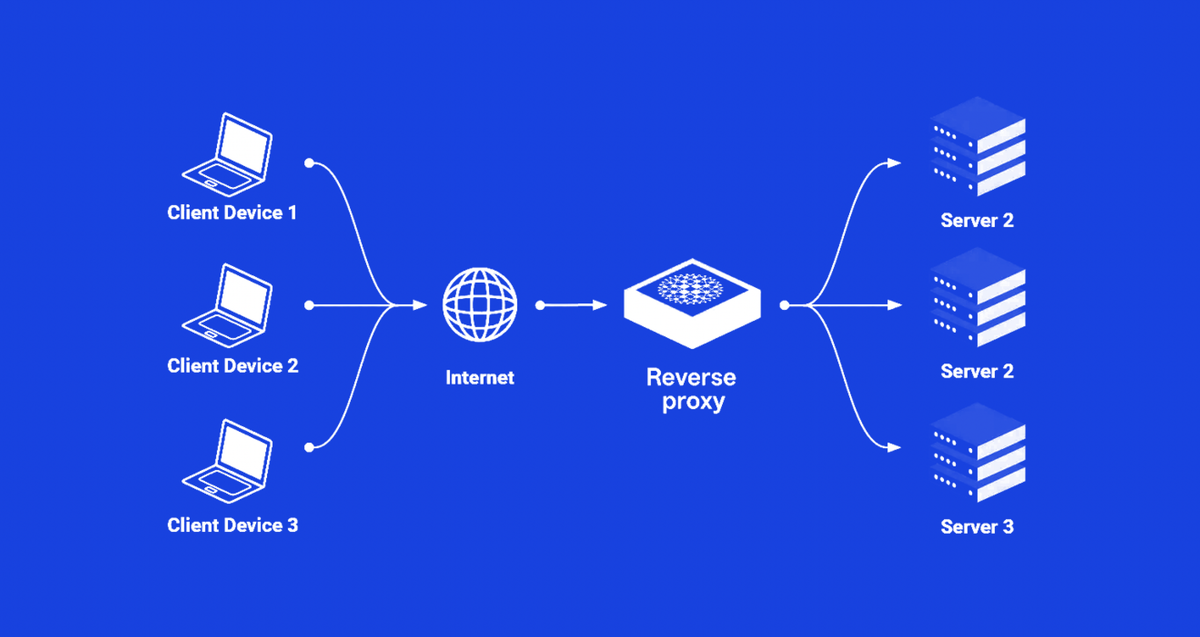
为什么要关注反向代理?
在大规模互联网服务架构中,反向代理往往是“隐形英雄”──它隐藏在用户点击和后端处理之间,为我们承担稳定性、安全性和性能优化的重任。无论是业界大厂的服务网格(Service Mesh),还是中小团队自建的流量分发层,反向代理都是必不可少的基础设施。
场景小故事
某电商双十一当天,突发数十万 RPS 峰值。正是靠前置的反向代理平滑了突增流量,自动剔除健康检查不通过的后端实例,让业务系统毫无感知地安全度过流量洪峰。
一、反向代理的「五大核心价值」
- 流量分发与弹性扩缩容
- 动态发现后端实例,自动做负载均衡
- 配合健康检查,实现故障实例“自动下线”
- 降维解耦与灰度发布
- 屏蔽后端地址、端口变化
- 通过路由规则实现灰度流量切分
- 安全防护
- Web 应用防火墙(WAF)、DDoS 缓解
- TLS 终端解密,减少后端压力
- 协议网关与转码
- HTTP/2、gRPC、TCP、UDP 混合支持
- 请求头、路径改写,协议转换
- 可观测性与治理
- 实时指标:QPS、延迟、错误率
- 分布式追踪埋点,配合 Prometheus、Zipkin 等
二、从 0 到 1:搭建你的第一个反向代理
下面示例以开源 Nginx 为例,展示如何用 5 行配置把客户端请求转发给后端服务。
worker_processes auto;
events { worker_connections 1024; }
http {
upstream backend {
server 10.0.0.11:8080;
server 10.0.0.12:8080 backup;
}
server {
listen 80;
location / {
proxy_pass http://backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
}
这段配置做了三件事:定义名为backend的后端实例组将所有 80 端口流量转到backend转发时保留 Host 和客户端 IP
对新手来说,最快的上手路径就是先把这几行写起来,验证“代理——转发——响应”流程跑通后,再逐步加限流、重写规则、TLS 配置。
三、进阶玩法:高并发下的性能制胜
3.1 非阻塞 I/O 与事件驱动
- 阻塞模式 在高并发下线程激增,频繁切换带来高额开销
- 非阻塞 + epoll 可轻松应对上万级连接,通过事件循环分发请求
Nginx、Envoy、HAProxy 等都采用事件驱动模型,各自对内核多路复用机制(epoll/kqueue)做了深度优化。
3.2 多核与多进程/多线程
- 多进程(NGINX 默认):多 Worker 进程共享监听端口,依赖内核分发。
- SO_REUSEPORT:在多进程/多线程场景下让内核更均衡地分配连接。
实践经验:在 32 核以上机器上,开启 reuseport 后通常能提升 10%~30% 的吞吐;但要注意上游连接分布均匀性,必要时可配合 session hash 或 consistent‑hash 进一步控制。
四、TLS 与协议落地:细节决定成败
- TLS 握手 本身就有 2~3 次 RTT,成为延迟大户。
- Session Resumption、0-RTT 可复用密钥,大幅减少握手开销。
- 多协议支持:当你的应用既有 HTTP,也有 WebSocket、gRPC,甚至原生 TCP/UDP 游戏服务,如何统一接入并做限流、认证,才是真正的考验。
Tip:Envoy 的 Filter Chain 机制能在同一个监听端口下,对不同协议做链式处理;而 Traefik 则提供动态配置、Docker/K8s 自动发现,适合微服务场景。
五、可观测性与运维实践
- 指标暴露:为每个请求记录延迟、状态码、带宽,并导出到 Prometheus。
- 日志采集:统一 JSON 格式日志,方便 ElasticSearch/Kibana 分析。
- 分布式追踪:在代理端插入 trace header(如 Zipkin、Jaeger),可视化调用链。
- 故障演练:定期进行故障注入(Chaos Monkey),验证代理在网络抖动、后端宕机等场景下的容错能力。
如何选型与落地
- 小团队、快速迭代:Traefik、Caddy 上手快,自动发现特性强。
- 大规模、高性能:Nginx、Envoy、HAProxy 经得起几百万 RPS 考验。
- 服务网格:Envoy + Istio/Linkerd,专注微服务互通与安全。
反向代理不仅仅是“转发工具”,而是现代云原生架构的流量中枢。理解其底层实现与最佳实践,既能让你在流量洪峰中稳如磐石,也能为后续的服务治理、安全审计和观测能力打下坚实基础。



