FD leak
Rust FD泄漏问题的排查与解决
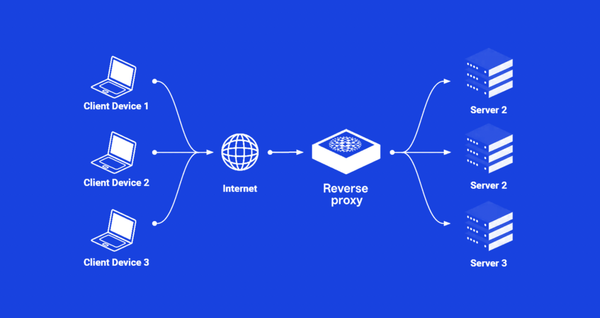
问题背景 在生产环境中运行的 Rust Web 服务出现了文件描述符(FD)持续增长的现象。服务使用 actix-web 框架,配合 SQLite 数据库(通过 sqlx)、Redis 缓存、以及 Tantivy 全文检索引擎。 初始监控数据显示: * 同一个数据库文件 data.db 被打开了多次(FD: 9, 10, 49, 52, 61) * 文件描述符总数在运行一段时间后持续增长 * 服务内存占用从 71.81 MB 增长到 305.30 MB 排查过程 1. 文件描述符分析 通过 Linux 系统工具进行详细排查: # 查看进程打开的文件描述符 ls -l /proc/